Introduction
Anonymization is the process of protecting private or sensitive information by erasing or encrypting identifiers that connect an ‘entity’ to stored data. If the anonymization is fool-proof, the process of Deanonymization should not reveal personal identifiable information. Typically, anonymization could be just pattern anonymization, or just the value anonymization, or both. In this work, we want to do just the value anonymization, so as to preserve the predictive/detective power. Just like any other data, even in Telco data, we will have to deal with both the categorical Variables and the numerical variables. There are various approaches under anonymization:
- Suppression
- Masking
- Pseudonymization
- Generalization
- Data Swapping
- Data Perturbation
- Synthetic Data
Typically, Synthetic data generation is considered as the most fool-proof among all the other approaches.
In this work, we want to answer the following questions:
- Do we have the datasets, which consists of the all the sensitive information?
- Well used, freely available, significant size, etc.
- What kind of sensitive information is well suited for each of the different techniques?
- Mapping of a type of sensitive information to a technique.
- Is there a single technique that is applicable to all kinds of sensitive information?
- Can we automatically identify the PII in the given dataset?
- Can we build a tool that takes in the dataset and anonymizes it automatically (with no manual intervention) using the best technique ?
Phases
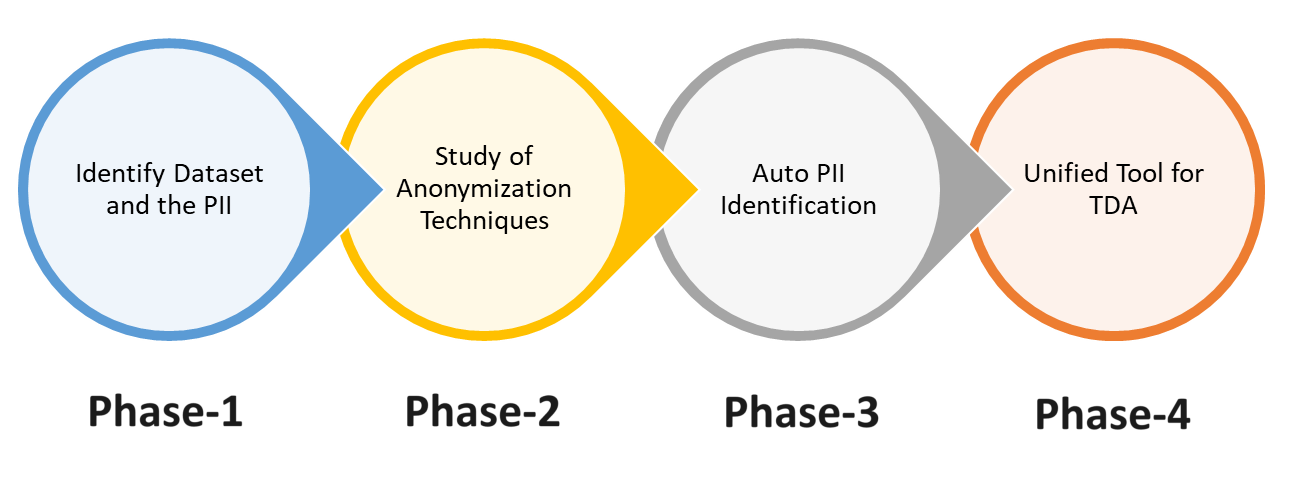
Phase-1
In this phase, we want to (a) agree on what constitute the ‘sensitive’ (PII) data. (b) agree on the exact dataset to use. (c) find the 'gaps' in datasets and try to fill it somehow.
What constitutes the PII information:
- Names (Systems, Domain, Individuals, Organizations, Places, etc.)
- Address (IP and MAC)
- Telco Fields - IMSI, IMEI, MSIN, MSISDN, MCC+MNC
- Location Data (Cell-ID, Count, etc.). GPS Data on its own is not a sensitive information. The context around that, such as 'names', are sensitive.
PII Type | Dataset (links) |
Names (Systems, Domain, Individuals, Organizations, Places, etc.) | |
Address (IP and MAC) | Internet Traffic Dataset: EX1, EX2 |
Telco Fields - IMSI, IMEI, MSIN, MSISDN, MCC+MNC | Adult Dataset enhanced with Telco-Fields Adult Dataset: Generate random IMEI/IMSI* fields and add it to this dataset |
Location Data (GPS, Cell-ID, Count, etc.) |
Phase-2
In this phase we would want to:
- Try available tools (Libraries) and techniques (implementations) on the chosen datasets.
- Find the gaps in tools and techniques.
- Fill those gaps considering the
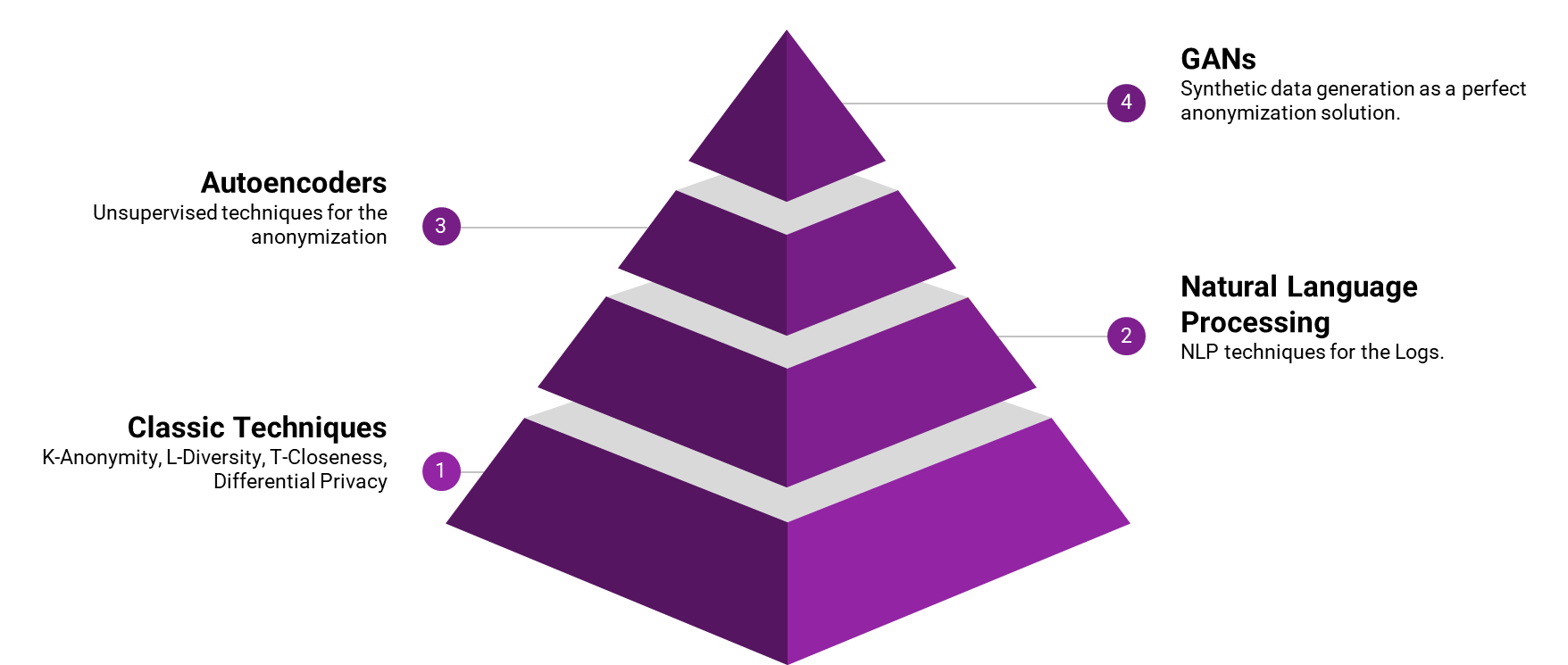
we will be evaluating the following techniques
- Classic (and its variations): K-Anonymity, L-Diversity, T-Closeness, Differential Privacy
- Data Anonymization with Autoencoders
- NLP approaches for data anonymization
- Generative AI (GANs)